5.5.2-代码解析:S01_sub_遍历文件¶
本过程对【1】输入文件夹下的文件进行遍历循环
1)当文件格式为TXT,调用sub_TXT文件解析,
2)当文件格式为其它格式,调用sub_excel文件解析
文件遍历完毕以后,所有数据全部写入数据库.xlsx文件时,调用sub_数据库排序,对数据库内容进行排序
代码如下
1 Sub S01_sub_遍历文件()
2 currentPath = ThisWorkbook.Path
3 Set fso = CreateObject("Scripting.FileSystemObject")
4 Set currentFolder = fso.GetFolder(currentPath)
5
6 ' 获取上一级文件夹地址
7 Set upperFolder = currentFolder.parentFolder
8 inputAddress = upperFolder & "\【1】输入"
9 backupAddress = upperFolder & "\【4】备份"
10
11 For Each fileObject In fso.GetFolder(inputAddress).Files
12 eachFileName = fileObject.Name
13 fileFirst4 = Mid(eachFileName, 1, 4)
14 fileFirst4Big = UCase(fileFirst4)
15 If fileFirst4Big = "TIME" Then
16 eachFileType = Split(eachFileName, ".")(1)
17 eachFileTypeBig = UCase(eachFileType)
18 If eachFileTypeBig = "TXT" Then
19 Call sub_TXT文件解析(inputAddress, eachFileName, backupAddress)
20
21 Else
22 Call sub_excel文件解析(inputAddress, eachFileName, backupAddress)
23 End If
24 End If
25
26 Next
27
28 ' 数据库数据排序
29 Call sub_数据库排序
30 End Sub
关键代码解读
1)第12行: eachFileName = fileObject.Name。获取被遍历文件的文件名。
2)第13-15行: 判断被遍历的文件是否是我们需要的文件
2.1)第13行:
fileFirst4 = Mid(eachFileName, 1, 4)。文件名为一个字符串,取出其前4个字母。2.2)第14行:
fileFirst4Big = UCase(fileFirst4)。将其转换为大写
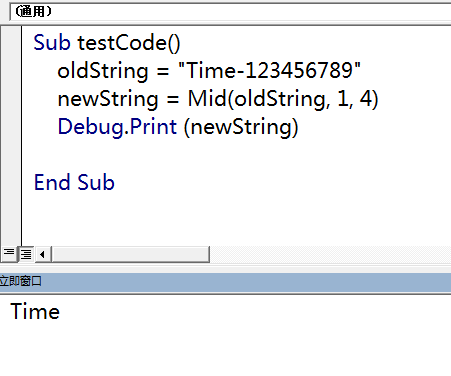
Mid(拟切片字符串,开始位置,拟截取长度)。以下示例获取拟截取字符串的前4位,运行结果如图5-17所示。
Sub testCode()
oldString = "Time-123456789"
newString = Mid(oldString, 1, 4)
Debug.Print (newString)
End Sub
3)第16行: eachFileType = Split(eachFileName, ".")(1)。本代码获取文件的格式。通过观察文件的命名规则,将文件名以点号(.)进行分割,分割后的数组中取位置为1的元素(该数组索引从0开始)